
After reading a particularly fascinating Wikipedia article on the processes of Metamemory (i.e. the mind thinking about its own memory), I could help but be drawn to the idea that some principles that guide the metacognitive processes of memory regulation can be used to create faster, more efficient and more accurate digital storage devices.
The following graph visually represents some major related areas to metamemory, and reveals the intricate relationship the subject has with various fields of cognitive science, psychology and philosophy (courtesy of Springer)
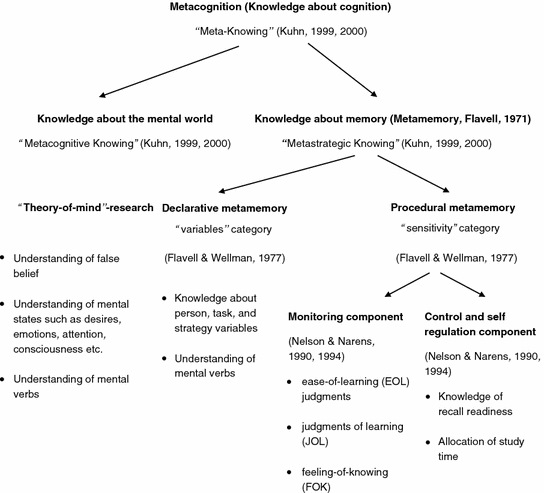
While the application of these strategies may be somewhat complicated by the way memory hierarchies differ between the mind and machine, the general principles can, in a sense, be used to save valuable digital work in memory recall, searching and retrieval. Perhaps the greatest difference between mental and digital memory is the fact that all mental memory is volatile to some degree. While a computer can rapidly assess whether or not it has access to some information based on a physical location on the storage medium, many metamemory processes are dedicated to this very determination. In other words, many of the control, monitoring and self-regulation components of metamemory serve the function of telling one what they know, don’t know and the probability of knowing without having to expend the mental energy associated with recall.
In some instances, however, especially relating to the semi-volatile and volatile forms of memory on computers, I contend that these very process could save valuable clock cycles if applied in the proper way to digital memory systems. Although the infantile days of programming where coders had to worry about managing every byte as efficiently as possible may long be over with the advancement of higher-speed memory technology (especially solid-state technology), certain algorithms of memory regulation and assessment could help speed up recall (or the lack thereof) by simply making a statistical judgment that determines the likelihood of the information being located in volatile memory. Thus, rather than looking through the entire series of memory address for a single file, the system can skip the locations where the likelihood of the file being there is low and focus on the more probable locations.
This consideration will become more significant in the future as file sizes increase and the burden of manually checking for the presence of information at a given address becomes more and more cumbersome. Furthermore, as machine learning advances, such metaprocesses will become indispensable in organizing and structuring the behavior of these dynamic systems.